| What are NAs? | Nucleoside analogues are structurally modified nucleosides, and this modification usually involves the pentose sugar. Nucleosides and deoxyribonucleosides are composed of nucleobases and ribose or deoxyribose in the form of glycosidic bonds. They are the basic components of ribonucleic acid (RNA) and deoxyribonucleic acid (DNA), and are the basis of genetic genes. In the human body, nucleoside analogues, through phosphorylation, become triphosphate nucleoside analogues, which have antiviral effects. They can inhibit the activity of the virus's DNA polymerase and reverse transcriptase; and competitively incorporate into the virus's DNA chain with nucleosides, terminating the extension and synthesis of the DNA chain, thereby inhibiting the replication of the virus and exerting antiviral effects. Nucleoside analogues are the largest and most important class of antiviral drugs. Acyclovir for treating herpes (HSV), Zidovudine, the first drug for treating AIDS (HIV), Entecavir for treating hepatitis B (HBV), and Gilead's star hepatitis C drug (HCV), Sofosbuvir, the most expensive pill in history, all belong to this class of drugs. |
|---|
| What's NA-DB |
|---|
| About NA-DB |
|
NA-DB is a public, web-accessible database that collects three types of chemical information related to nucleoside analogs (NAs), including compound names, chemical representations of molecular structures, and physicochemical properties. The compound names include their identifier numbers in the NA-DB and ChEMBL databases, as well as the generic names of the compounds, if available. The chemical representations of molecular structures include SMILES strings, InChI, InChI Key, and molecular formulas. The physicochemical properties include molecular weight, exact mass, heavy atom count, ring count, number of hydrogen bond donors, number of hydrogen bond acceptors, number of rotatable bonds, and topological polar surface area. The latter two types of information were generated using the RDKit toolkit.
The biological data collected in the NA-DB database primarily includes the activity information of NAs at the protein and cellular levels. The activity data can be represented as Ki, IC50, GI50, EC50, CC50, and the CC50/EC50 ratio. |
| Target and Drug Information |
|
The database provides comprehensive information about targets and their associations with nucleoside drugs and clusters. This information is visualized through various charts and diagrams to facilitate better understanding of the relationships between targets, drug clusters, and approved nucleoside drugs. 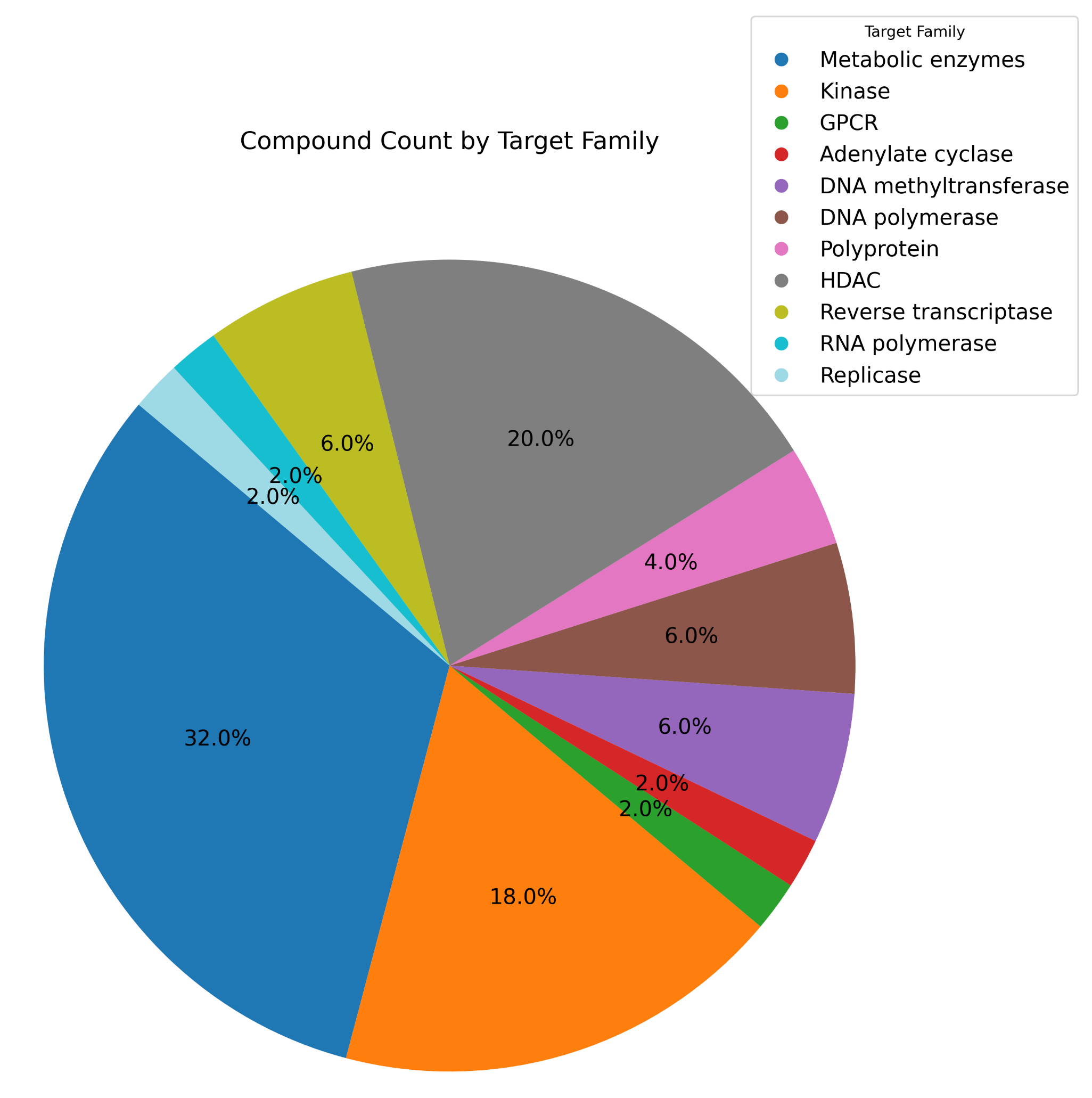
Target family pie chart 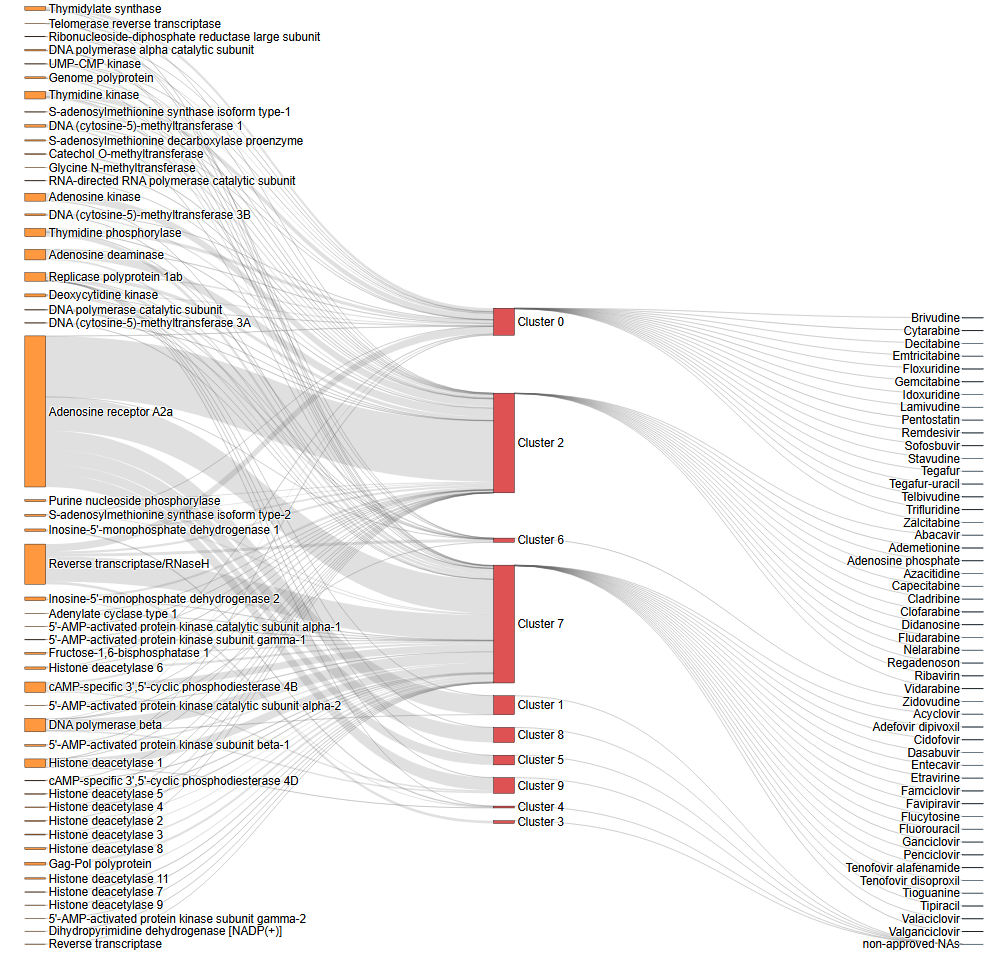
Sankey diagram to illustrate the associations among target name, NA clusters and approved nucleoside drugs. 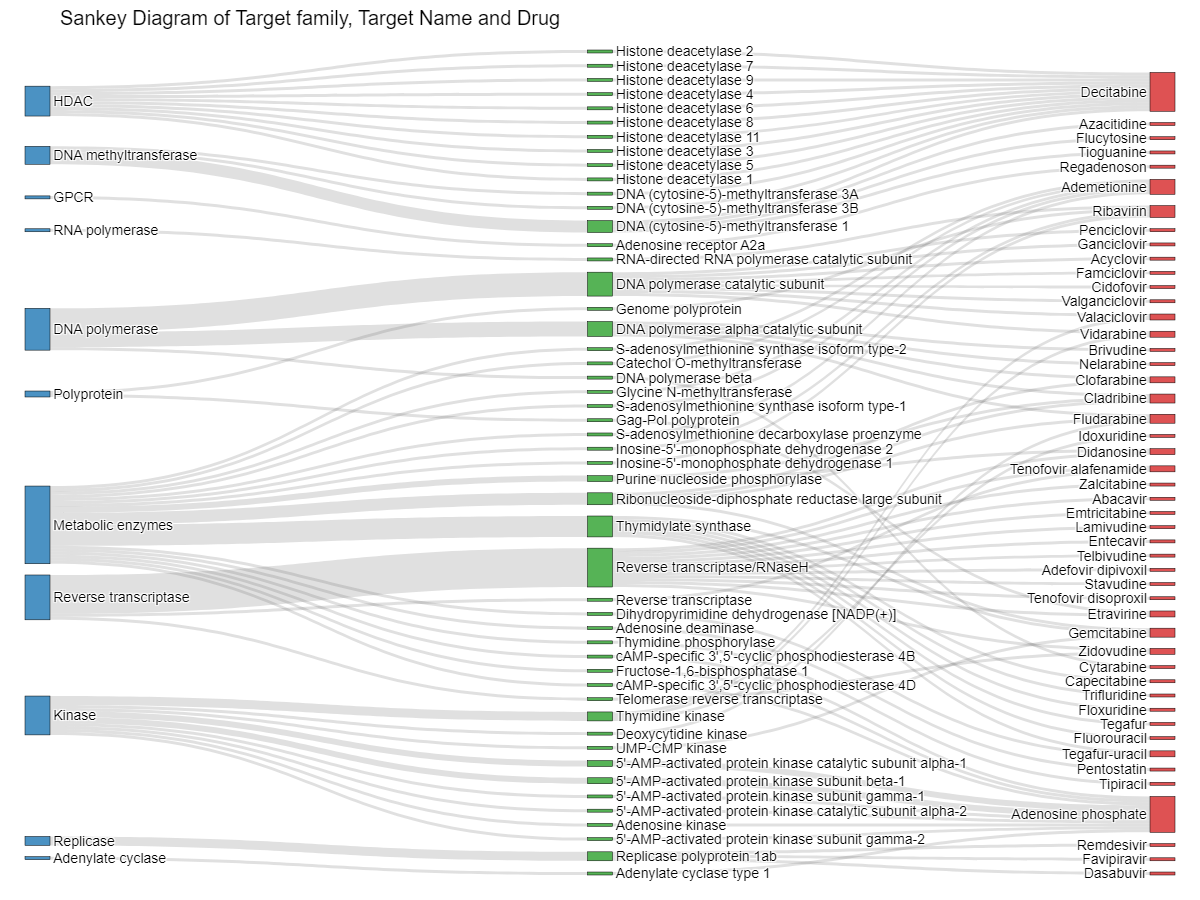
Sankey diagram to illustrate the associations among target family, target name and approved nucleoside drugs. |
| Search |
|
TEXT-BASED SEARCH: First, select whether to search for a compound or a base/pentose fragment. Then, you can choose to search based on name or ID, or by using a SMILES string. When performing a search using SMILES, you can further refine your search by selecting either substructure matching or similarity search. If similarity search is chosen, you can then specify which fingerprint algorithm to use for calculating molecular similarity. 
STRUCTURE-BASED SEARCH: Users can also click the "Draw Structure" button to manually draw molecular structures. The drawn structure will be automatically converted into a SMILES string and displayed in the search box, allowing for further search operations. 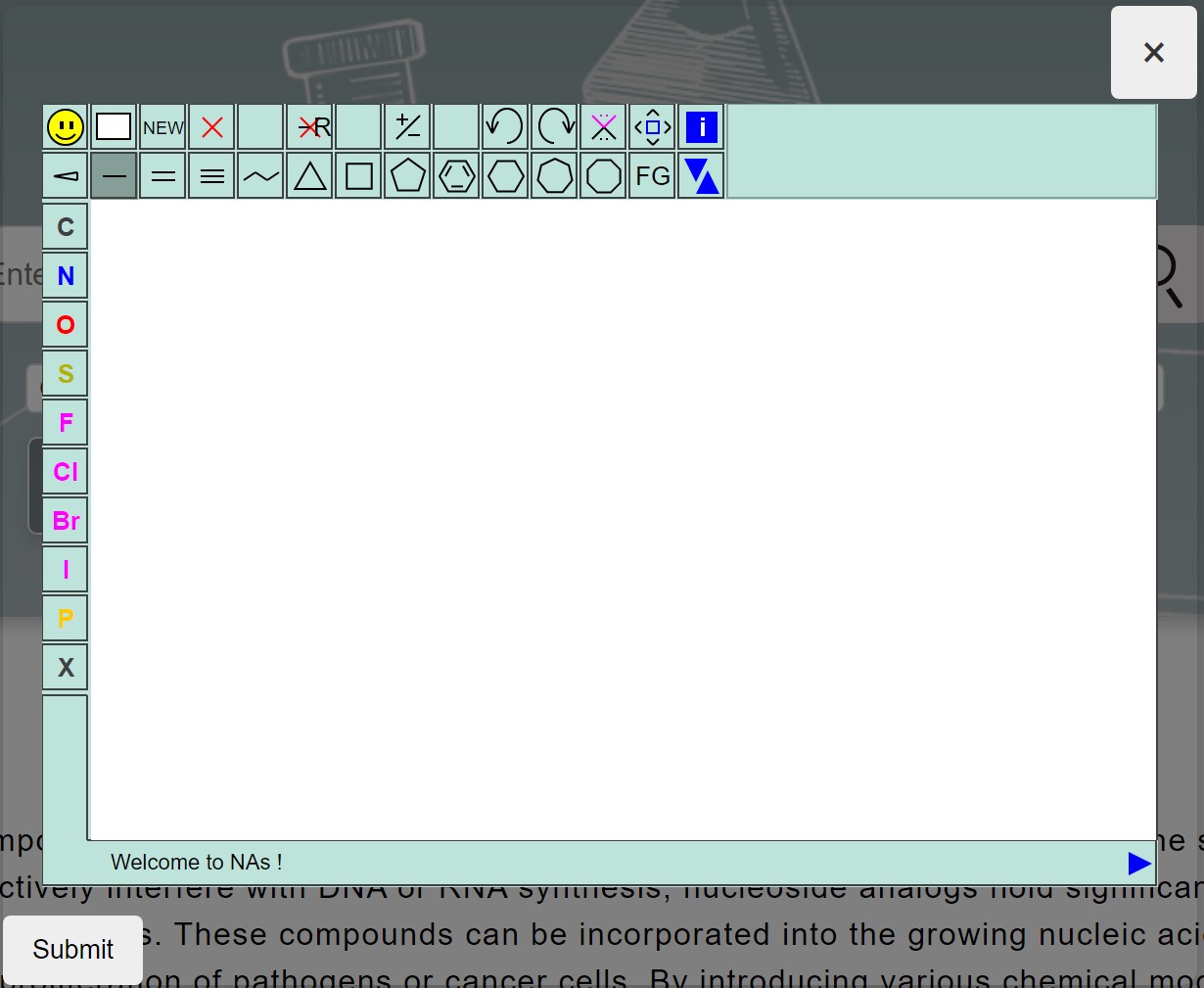
|
| Compound |
|
On the compound browsing page, users can view the activity data of various compounds and further refine and pinpoint the desired data using the filtering options provided at the top of the page. Additionally, a download function is available in the upper right corner, allowing users to conveniently obtain the required data. By clicking on a specific compound, the system navigates to the compound's detailed information page, where its physicochemical properties and activity data are displayed. 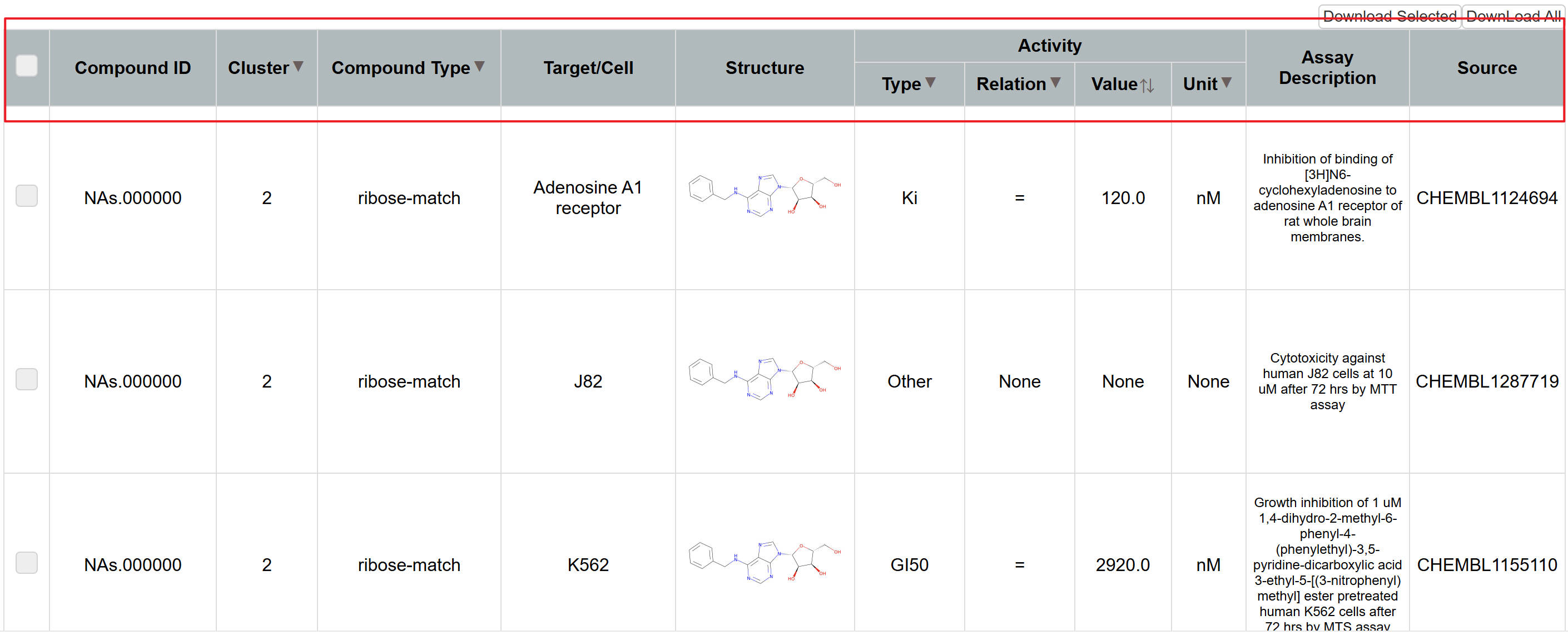
Within the detailed information page, users can locate the "Functional Fragments" section. By clicking the "Details" button, they are directed to the corresponding fragment page. Moreover, the "Related Compound ID" link enables users to access the activity data browsing page for compounds containing the same fragment, facilitating further data analysis and exploration. 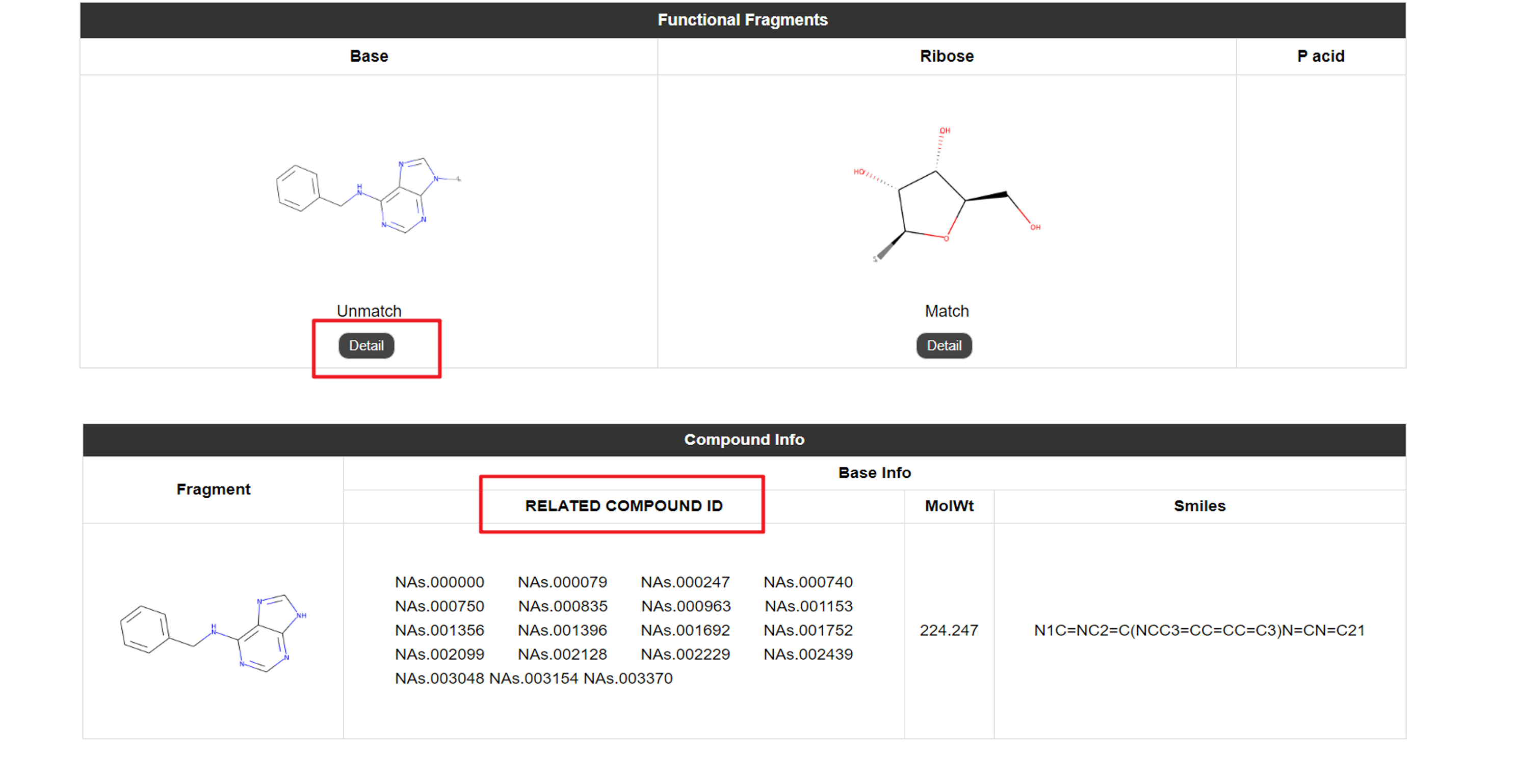
|
| Fragment |
|
In the base/ribose fragment browsing interface, users can view the 2D structure of the fragments and apply basic filtering through the "Type" option to refine the displayed information. Additionally, the platform provides a data download function, allowing users to easily obtain the required information. Upon clicking a specific fragment, the system navigates to the detailed information page of that fragment. Furthermore, users can access links to pages containing compounds associated with the fragment, enabling further exploration of the related compounds' activity data. 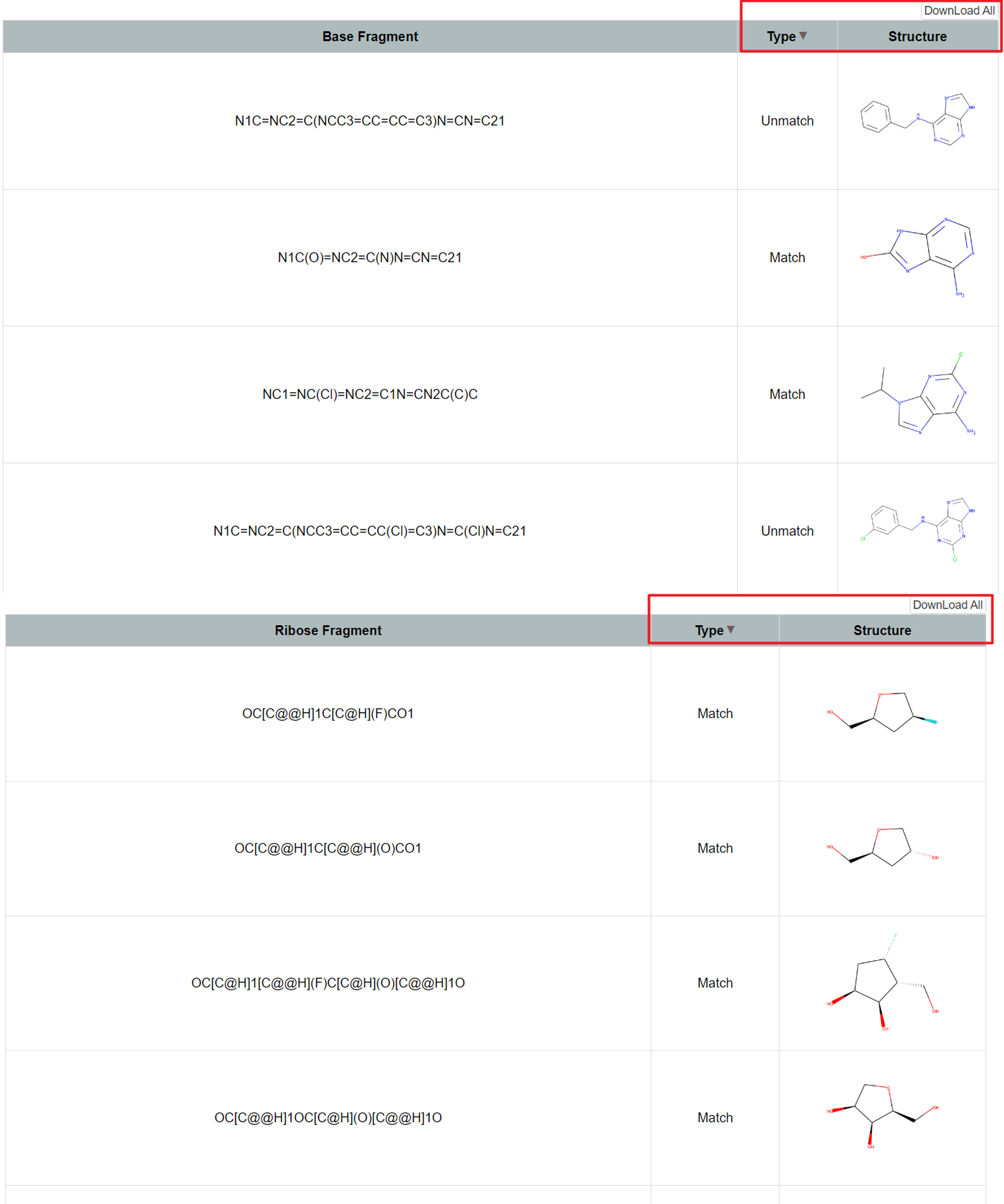
|
| Case study of molecule design with NA-DB |
|
One example is presented here, where the uracil substructure was searched among ligands of HIV-1 Reverse Transcriptase. Among these active compounds, several contain a 3-hydroxyl substituted uracil, demonstrating that this modification pattern can be applied to ligands of another target, the Gag-Pol Polyprotein. This case study illustrates how NA-DB search results can reveal medicinal chemistry strategies on nucleotide scaffolds and inspire cross-target design knowledge transfer. 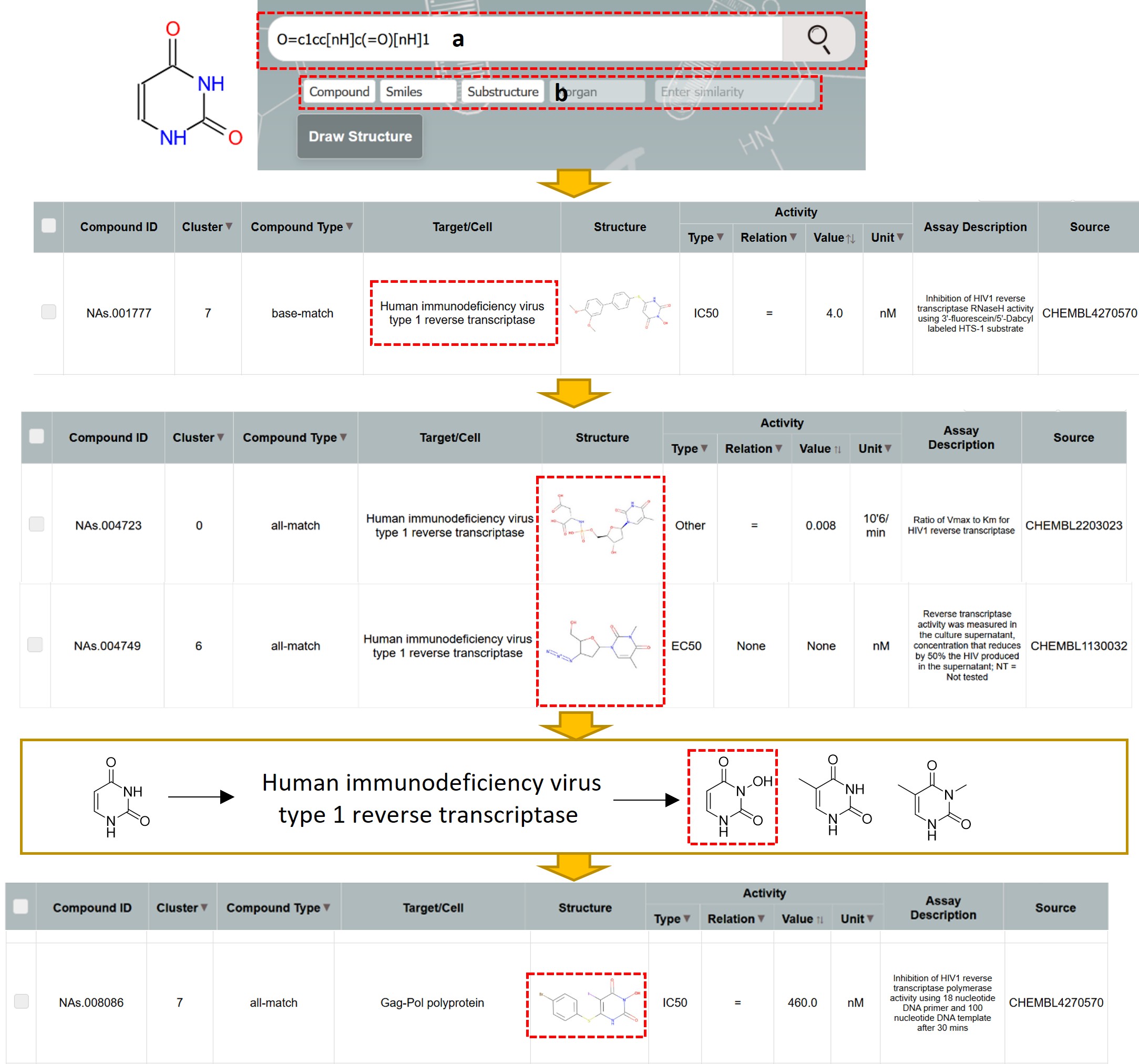
|